Research
The overarching theme of the LLRM project revolves around a principle known as bottom-up verification: lifting higher-level, semantically equivalent code representations from legacy machine code for formally verifying their security properties. This principle is enabled through formalization of instruction-set semantics, decompilation to higher abstraction levels, and verification of security properties using machine-generated mathematical proofs. Formal proofs are machine-generated and checked using a theorem-prover tool (e.g., Isabelle/HOL).
The bottom-up verification principle is motivated by the observation that bottom-up reasoning and verification may be the only available option for (formally) reasoning about security properties (and patching vulnerabilities or hardening) when source/library codes are unavailable. Even when source/library code is available, outdated build processes and the lack of backward compatibility in libraries challenge top-down methods. The approach also has a positive side effect on the trusted computing base: the trust base excludes compilers, assemblers, linkers, and runtimes, which are typically trusted by top-down verification methods. In addition, formalization of instruction semantics – necessary for reasoning about machine code – is relatively more straightforward to realize than formalizing programming language semantics. (Top-down methods need formal programming language semantics, and relatively few languages have formal semantics.)
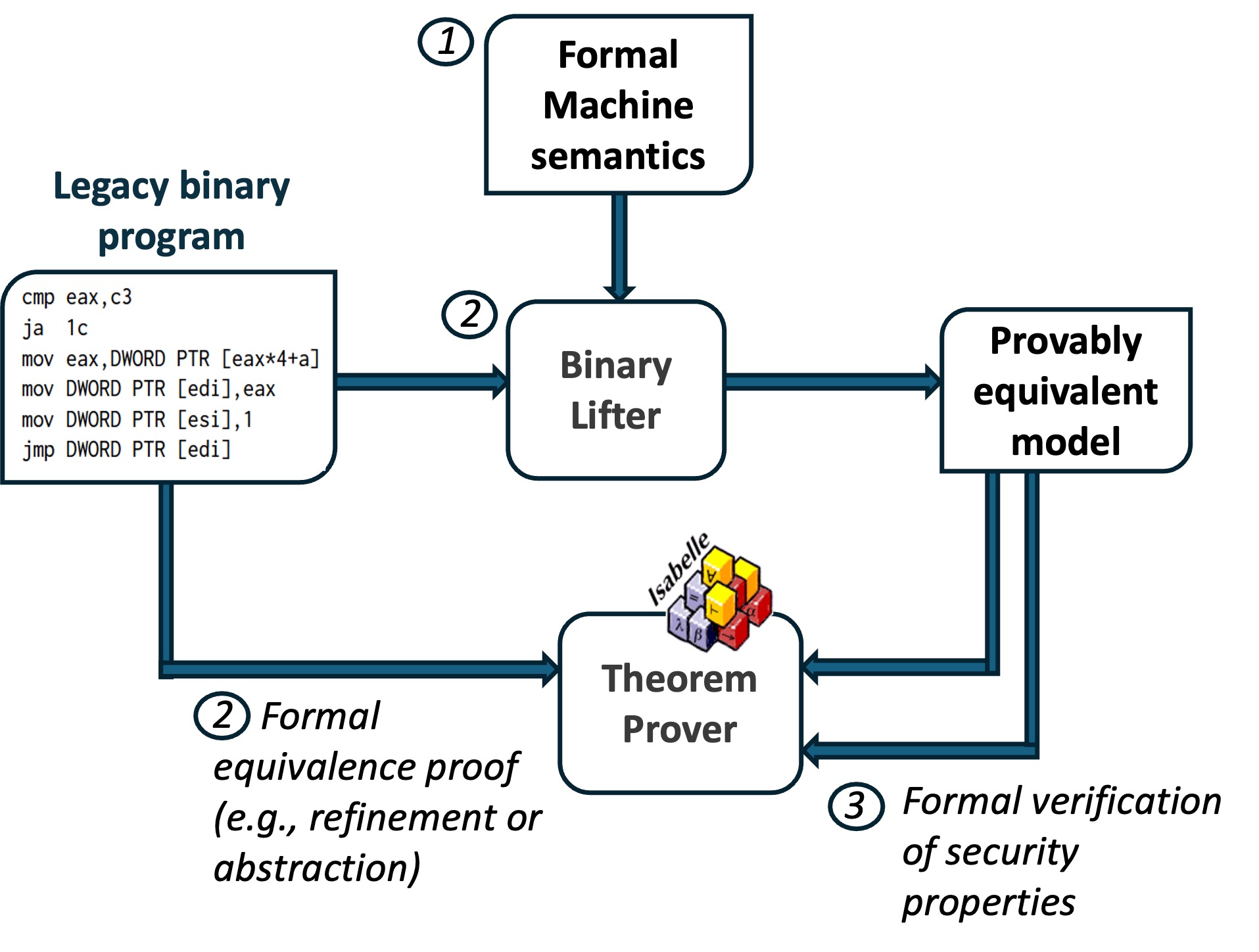 Bottom-up verification methodology broadly follows a three-step approach. The first step is the formalization of instruction semantics of ISAs such as x86-64 and aarch64. This is followed by binary lifting, i.e., lifting a model of the machine code that is provably semantically equivalent to the machine code. Example models include symbolized assembly, memory model, LLVM IR, and even C. Formal proofs are typically machine-generated and checked using a theorem-prover tool (e.g., Isabelle/HOL). The third and final step is the verification of security properties on the lifted model. Since the model is provably semantically equivalent to the input machine code, properties verified on the model hold for the machine code. Example security properties include stack integrity, heap integrity, control flow integrity, and adherence to calling conventions. Formal proofs are also machine-generated and machine-checked.
Bottom-up verification methodology broadly follows a three-step approach. The first step is the formalization of instruction semantics of ISAs such as x86-64 and aarch64. This is followed by binary lifting, i.e., lifting a model of the machine code that is provably semantically equivalent to the machine code. Example models include symbolized assembly, memory model, LLVM IR, and even C. Formal proofs are typically machine-generated and checked using a theorem-prover tool (e.g., Isabelle/HOL). The third and final step is the verification of security properties on the lifted model. Since the model is provably semantically equivalent to the input machine code, properties verified on the model hold for the machine code. Example security properties include stack integrity, heap integrity, control flow integrity, and adherence to calling conventions. Formal proofs are also machine-generated and machine-checked.
libLISA: Automated discovery of CPU instruction semantics.
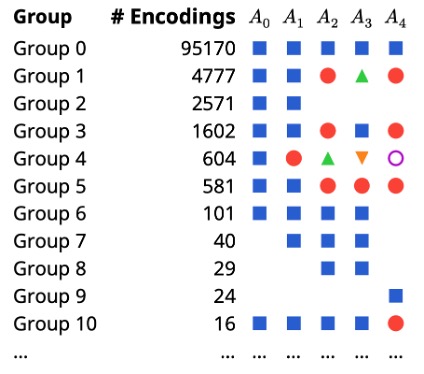
 libLISA is a tool that can fully automatically discover executable instructions on a CPU and synthesize their semantics. The tool requires minimal human input: only a description of the CPU state (no ISA manuals, assemblers, or disassemblers) is needed, and it outputs a list of executable instructions along with their semantics. libLISA discovers instructions through enumeration and mapping to equivalence classes. libLISA has achieved breakthrough results! It has discovered instructions unknown to (x86) instruction manuals, assemblers, and disassemblers! In addition, it has discovered instructions that exist only on two (x86) CPU architectures and that different instructions behave differently on different architectures! Check out libLISA here.
libLISA is a tool that can fully automatically discover executable instructions on a CPU and synthesize their semantics. The tool requires minimal human input: only a description of the CPU state (no ISA manuals, assemblers, or disassemblers) is needed, and it outputs a list of executable instructions along with their semantics. libLISA discovers instructions through enumeration and mapping to equivalence classes. libLISA has achieved breakthrough results! It has discovered instructions unknown to (x86) instruction manuals, assemblers, and disassemblers! In addition, it has discovered instructions that exist only on two (x86) CPU architectures and that different instructions behave differently on different architectures! Check out libLISA here.
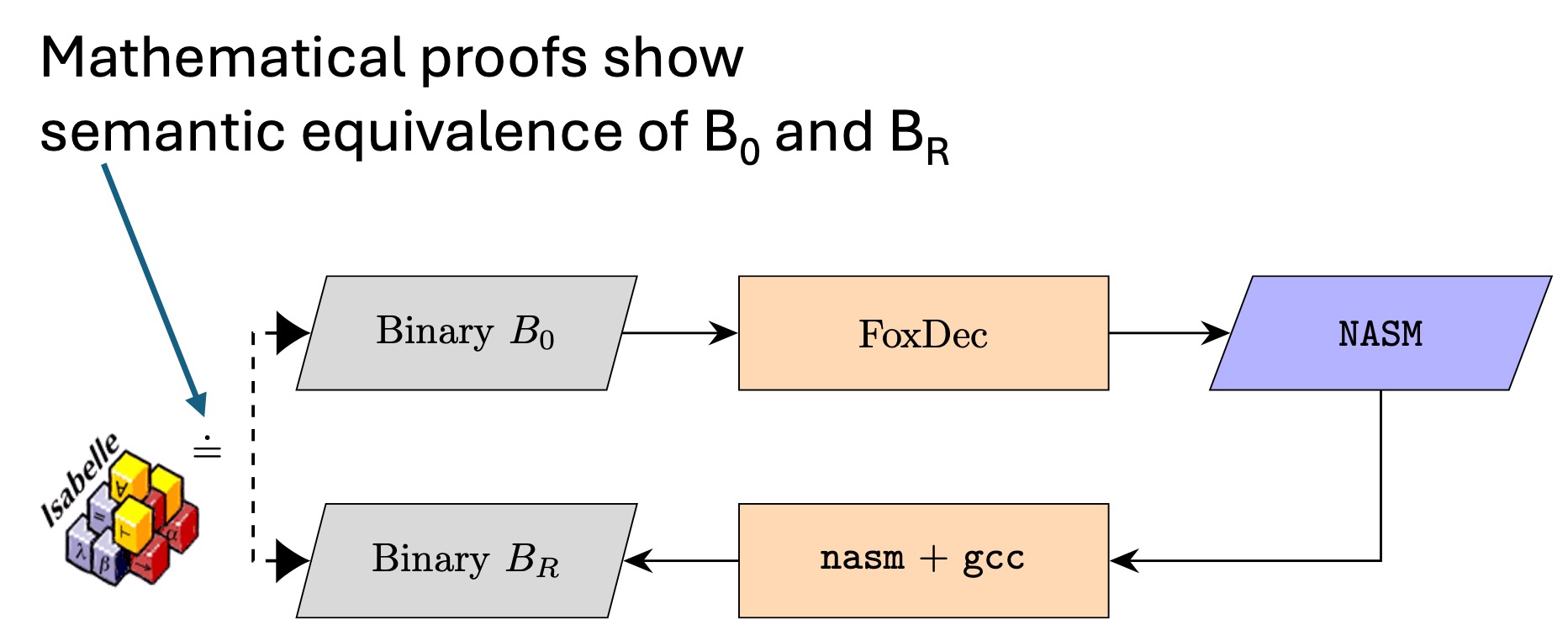 FoxDec 3.0: Formally verified x86-64 Decompiler. FoxDec is a trustworthy decompiler of x86-64 binaries with no source code. It lifts a x86-64 binary B0 into NASM (netwide assembler) representation, which is a dialect of x86-64 assembly. The lifted NASM code is provably correct. This is demonstrated by recompiling the lifted NASM code using off-the-shelf compilation toolchains into a binary Br. Machine-generated proofs show the semantic equivalence of binaries B0 and Br. FoxDec’s trust base includes the prover tool used for generating proofs (i.e., Isabelle/HOL). The trust base excludes FoxDec’s lifting algorithms and implementation, as well as the compiling, assembling, and linking toolchains for producing binary Br from NASM. FoxDec enables trustworthy binary patching and hardening. Check out FoxDec 3.0 here.
FoxDec 3.0: Formally verified x86-64 Decompiler. FoxDec is a trustworthy decompiler of x86-64 binaries with no source code. It lifts a x86-64 binary B0 into NASM (netwide assembler) representation, which is a dialect of x86-64 assembly. The lifted NASM code is provably correct. This is demonstrated by recompiling the lifted NASM code using off-the-shelf compilation toolchains into a binary Br. Machine-generated proofs show the semantic equivalence of binaries B0 and Br. FoxDec’s trust base includes the prover tool used for generating proofs (i.e., Isabelle/HOL). The trust base excludes FoxDec’s lifting algorithms and implementation, as well as the compiling, assembling, and linking toolchains for producing binary Br from NASM. FoxDec enables trustworthy binary patching and hardening. Check out FoxDec 3.0 here.
FoxDec 2.0: Stack Integrity and CFI Verifier.
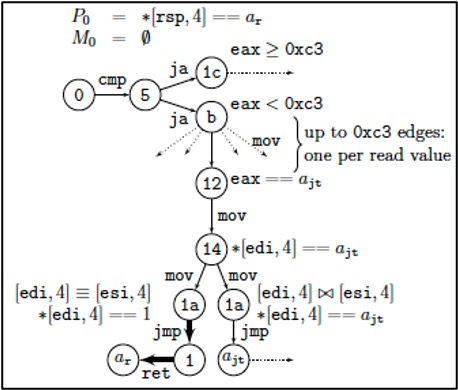 This version of FoxDec verifies a class of memory safety properties of x86-64 binaries, including return address integrity, bounded control flow, and adherence to the calling convention, without requiring source code. FoxDec lifts a provably overapproximative model called the Hoare Graph, which captures all possible control flow behaviors of a binary, including both programmer-intended and unintended behaviors. The lifted Hoare’s Graph (overapproximative) correctness is established using machine-generated proofs. FoxDec is highly scalable, with a nearly linear relationship between the number of computational steps and the number of instructions in a binary. FoxDec was demonstrated on the Xen hypervisor with ~450K instructions, which was the largest off-the-shelf binary verified in the literature at the time of publication. FoxDec’s trust base includes the prover tool used for generating proofs, and excludes the lifting algorithms and implementation. Check out FoxDec 2.0 here.
This version of FoxDec verifies a class of memory safety properties of x86-64 binaries, including return address integrity, bounded control flow, and adherence to the calling convention, without requiring source code. FoxDec lifts a provably overapproximative model called the Hoare Graph, which captures all possible control flow behaviors of a binary, including both programmer-intended and unintended behaviors. The lifted Hoare’s Graph (overapproximative) correctness is established using machine-generated proofs. FoxDec is highly scalable, with a nearly linear relationship between the number of computational steps and the number of instructions in a binary. FoxDec was demonstrated on the Xen hypervisor with ~450K instructions, which was the largest off-the-shelf binary verified in the literature at the time of publication. FoxDec’s trust base includes the prover tool used for generating proofs, and excludes the lifting algorithms and implementation. Check out FoxDec 2.0 here.
 FoxDec 1.0: Verified C Decompiler.
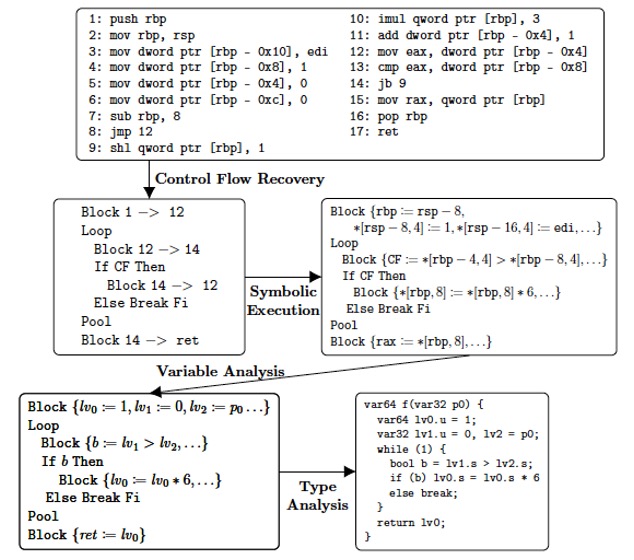
This (first) version of FoxDec is a verified C decompiler of x86-64 binaries with no source code. It is provably sound: extracted C code behaves the same as the original binary and is provably recompilable: extracted C code can be recompiled to produce an executable binary. Soundness and recompilability are established using machine-generated proofs. FoxDec 1.0 broke new ground in that it is the first published verified C decompiler. Formal methods are used in three decompilation phases: control flow recovery, symbolic execution, and variable recovery. FoxDec was demonstrated for four use cases: binary patching (patching a memory leak), binary porting (porting a binary to a different architecture), binary analysis (verifying stack integrity), and binary improvement (improving performance). Check out FoxDec 1.0 here.
FoxDec 1.0: Verified C Decompiler.
This (first) version of FoxDec is a verified C decompiler of x86-64 binaries with no source code. It is provably sound: extracted C code behaves the same as the original binary and is provably recompilable: extracted C code can be recompiled to produce an executable binary. Soundness and recompilability are established using machine-generated proofs. FoxDec 1.0 broke new ground in that it is the first published verified C decompiler. Formal methods are used in three decompilation phases: control flow recovery, symbolic execution, and variable recovery. FoxDec was demonstrated for four use cases: binary patching (patching a memory leak), binary porting (porting a binary to a different architecture), binary analysis (verifying stack integrity), and binary improvement (improving performance). Check out FoxDec 1.0 here.
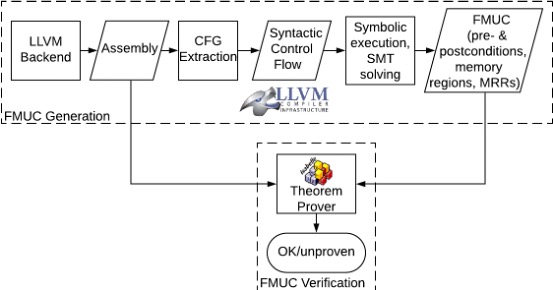
Luce: LLVM with formal memory Usage CErtificates. Luce computes memory usage certificates (FMUCs) for x86-64 binaries without source code. FMUCs are provably overapproximative: they include all memory regions that the binary can potentially modify. This is established using machine-generated proofs. FMUCs can be used to verify memory corruption exploits. Examples include verifying the integrity of return addresses and detecting stack and heap buffer overflows. Luce is integrated as an LLVM compiler pass. Luce’s capabilities were demonstrated on operating systems and hypervisors with over 10,000 instructions: the Hermit operating system (previously, the HermitCore library OS) and components of the Xen hypervisor, which were the most significant such demonstration at the time of publication. Check out Luce here.

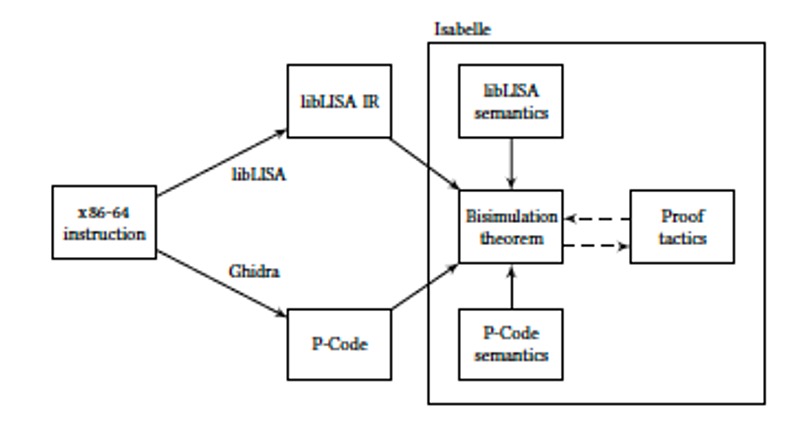 Verified Ghidra. This work is developing a formally verified method for lifting (x86-64) binaries to Ghidra’s P-Code. Ghidra is a binary lifter, developed by NSA and open-sourced, and P-Code is Ghidra’s intermediate representation. The lifter ensures that Ghidra’s P-Code, lifted from binaries, is trustworthy. This is established by automatically proving the semantic equivalence between the input binary and the lifted P-Code using machine-generated proofs. The work uncovered shortcomings in Ghidra’s P-Code and lifting (which were acknowledged/fixed by NSA). The trust base excludes the lifting algorithms and implementation. The tool enables trustworthy binary analysis, patching, and hardening using Ghidra. Check out poster paper here.
Verified Ghidra. This work is developing a formally verified method for lifting (x86-64) binaries to Ghidra’s P-Code. Ghidra is a binary lifter, developed by NSA and open-sourced, and P-Code is Ghidra’s intermediate representation. The lifter ensures that Ghidra’s P-Code, lifted from binaries, is trustworthy. This is established by automatically proving the semantic equivalence between the input binary and the lifted P-Code using machine-generated proofs. The work uncovered shortcomings in Ghidra’s P-Code and lifting (which were acknowledged/fixed by NSA). The trust base excludes the lifting algorithms and implementation. The tool enables trustworthy binary analysis, patching, and hardening using Ghidra. Check out poster paper here.